
Recent advancements in controllable human image generation have led to zero-shot generation using structural signals (e.g., pose, depth) or facial appearance. Yet, generating human images conditioned on multiple parts of human appearance remains challenging. Addressing this, we introduce Parts2Whole, a novel framework designed for generating customized portraits from multiple reference images, including pose images and various aspects of human appearance. To achieve this, we first develop a semantic-aware appearance encoder to retain details of different human parts, which processes each image based on its textual label to a series of multi-scale feature maps rather than one image token, preserving the image dimension. Second, our framework supports multi-image conditioned generation through a shared self-attention mechanism that operates across reference and target features during the diffusion process. We enhance the vanilla attention mechanism by incorporating mask information from the reference human images, allowing for precise selection of any part. Extensive experiments demonstrate the superiority of our approach over existing alternatives, offering advanced capabilities for multi-part controllable human image customization.
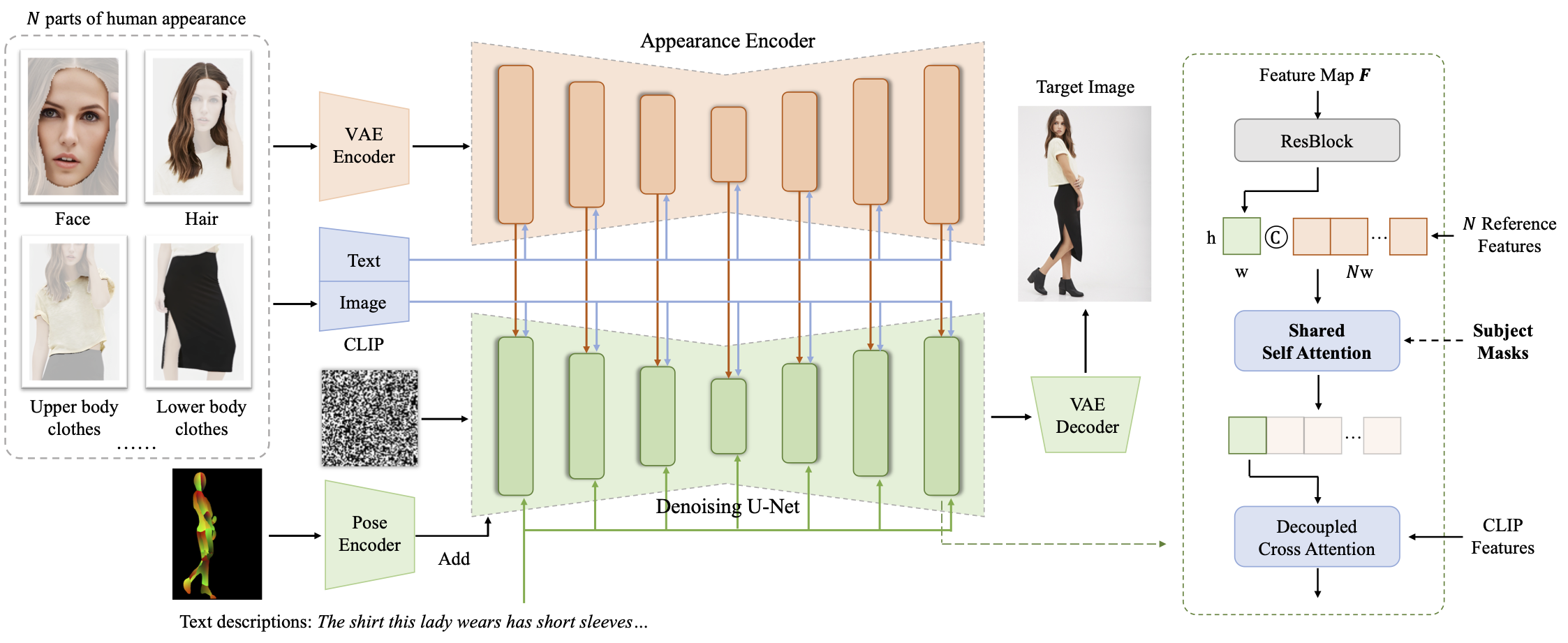
Overview of Parts2Whole. Based on the text-to-image diffusion model, our method designs an appearance encoder for encoding various parts of human appearance into multi-scale feature maps. We build this encoder by copying the network structure and pretrained weights from denoising U-Net. Features obtained from reference images with their textual labels are injected into the generation process by shared attention mechanism layer by layer. To precisely select the specified parts from reference images, we enhance the vanilla self-attention mechanism by incorporating subject masks in the reference images. Illustration of one block in U-Net is shown on the right part.

Parts2Whole supports generating human images conditioned on selected parts from different humans as control conditions. For example, the face from person A, the hair or headwear from person B, the upper clothes from person C, and the lower clothes from person D.
Parts2Whole supports generating human images from varying numbers of condition images, such as single hair or face input, or arbitrary combinations like "Face + Hair", "Face + Clothes", and "Upper body clothes + Lower body clothes".
@misc{huang2024parts2whole,
title={From Parts to Whole: A Unified Reference Framework for Controllable Human Image Generation},
author={Huang, Zehuan and Fan, Hongxing and Wang, Lipeng and Sheng, Lu},
journal={arXiv preprint arXiv:2404.15267},
year={2024}
}