Method
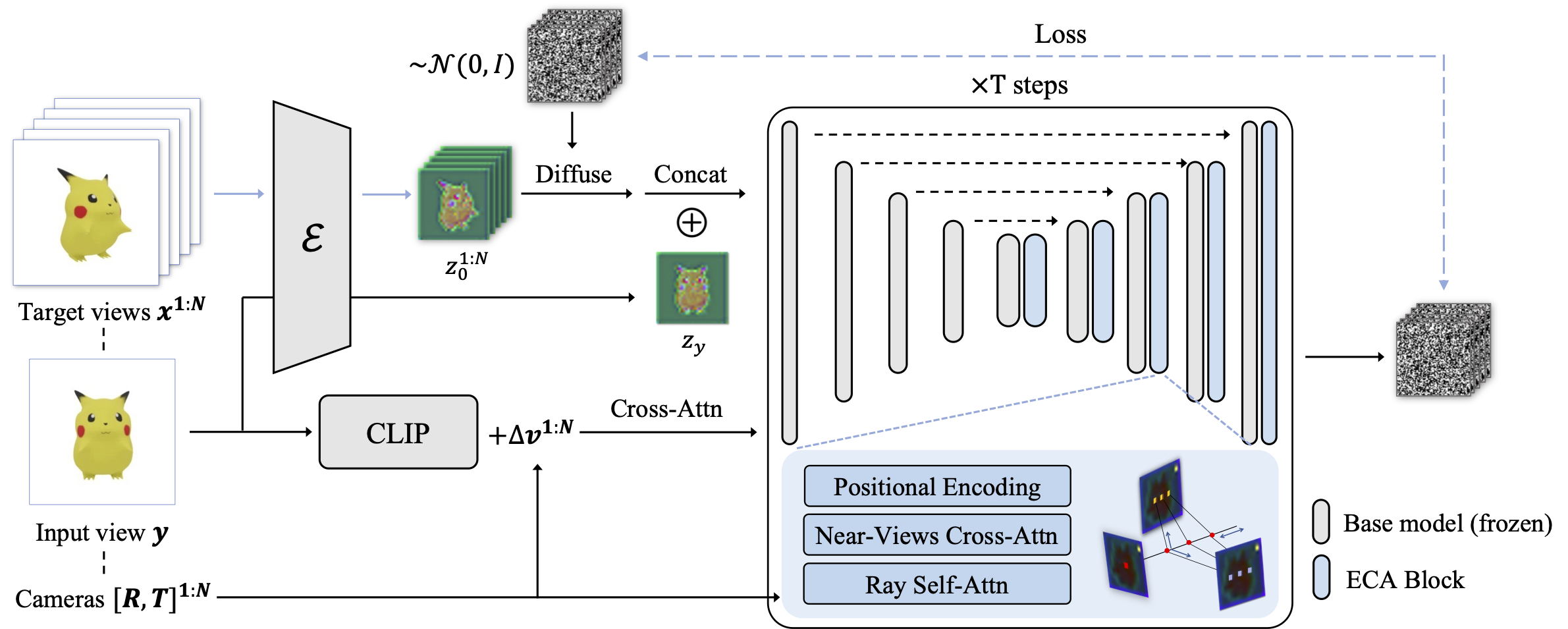
Pipeline of EpiDiff. Our method designs a module for modeling consistency, which is inserted into the base diffusion model.
Generating multiview images from a single view facilitates the rapid generation of a 3D mesh conditioned on a single image. Recent methods that introduce 3D global representation into diffusion models have shown the potential to generate consistent multiviews, but they have reduced generation speed and face challenges in maintaining generalizability and quality. To address this issue, we propose EpiDiff, a localized interactive multiview diffusion model. At the core of the proposed approach is to insert a lightweight epipolar attention block into the frozen diffusion model, leveraging epipolar constraints to enable cross-view interaction among feature maps of neighboring views. The newly initialized 3D modeling module preserves the original feature distribution of the diffusion model, exhibiting compatibility with a variety of base diffusion models. Experiments show that EpiDiff generates 16 multiview images in just 12 seconds, and it surpasses previous methods in quality evaluation metrics, including PSNR, SSIM and LPIPS. Additionally, EpiDiff can generate a more diverse distribution of views, improving the reconstruction quality from generated multiviews.
Pipeline of EpiDiff. Our method designs a module for modeling consistency, which is inserted into the base diffusion model.
For the target view, we use cross attention to aggregate epipolar line features from nearby views, and self attention to fuse spatial points into pixel features.
During training, we randomly sample 16 views out of the 96 rendered views. For evaluation, we select 16 views in two different settings: one with a fixed elevation of 30°, and another with uniformly distributed elevations.
@article{huang2023epidiff,
title={EpiDiff: Enhancing Multi-View Synthesis via Localized Epipolar-Constrained Diffusion},
author={Huang, Zehuan and Wen, Hao and Dong, Junting and Wang, Yaohui and Li, Yangguang and Chen, Xinyuan and Cao, Yan-Pei and Liang, Ding and Qiao, Yu and Dai, Bo and others},
journal={arXiv preprint arXiv:2312.06725},
year={2023}
}